
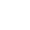

计算机学院网络与高能效计算研究所在计算机系统顶级会议上取得重要突破,共计有2篇论文被SOSP’25接收、 1 篇论文被 OSDI’25 接收、以及4篇论文被 USENIX ATC’25 接收,研究成果涵盖多个领域,充分展现了我所在计算机系统研究方面的综合实力。以下是会议和论文的简要介绍:
第32届ACM操作系统原理大会SOSP(ACM Symposium on Operating Systems Principles)录用结果近日揭晓。SOSP自1967年创办以来已有50多年历史,与OSDI并称为计算机系统领域最具影响力的两大学术会议。本届会议共收到368篇投稿,录用66篇,录取率为17.9%。
同期,由USENIX主办的计算机系统顶级国际会议——OSDI(Operating Systems Design and Implementation)和ATC(Annual Technical Conference)于7月7日至9日在美国波士顿联合举行。两者均为CCF推荐的A类会议,吸引了来自全球顶尖高校、科研机构和企业的投稿。本届OSDI共收到339篇投稿,录用53篇,接收率为16%;本届ATC共收到634篇论文投稿,录用100篇,接收率为15.8%。
一、面向用户态中断的高速安全存储栈(SOSP)
随着存储介质延迟的大幅下降,传统内核态存储栈难以充分利用现代SSD的性能,而现有用户态存储栈虽然具备更高性能,却无法安全地共享资源或高效调度任务。论文《Aeolia: Fast and Secure Userspace Interrupt-Based Storage Stack》提出了一个支持用户态中断的存储栈系统,在保证高I/O性能的同时实现安全高效的多任务资源共享。Aeolia挑战传统“用户态只能用polling”的认知,发现中断机制性能相近却更易实现资源共享与多核协同。系统基于Intel UINTR实现用户态中断传送,结合MPK可信隔离与Linux sched_ext调度框架,实现高性能且安全的用户态存储栈。基于Aeolia设计的高性能文件系统AeoFS,在多项基准测试中显著优于现有方案,最高性能提升达19.1×。该研究为构建可安全共享资源、具备多核可扩展性的用户态高性能存储栈提供了新方向,并验证了用户中断在存储系统设计中的实际可行性。该论文第一作者为北京大学计算机学院的博士生李传东,作者包括其导师汪小林教授、罗英伟教授和周迪宇助理教授(通讯作者)计算机学院数据所张杰助理教授,博士生衣然,硕士生张棕浩,来自密歇根理工大学的王振林教授,来自微软亚洲研究院的刘璟研究员以及Igalia的Changwoo Min。
二、CortenMM: 高效、强正确性保障的内存管理系统(SOSP)
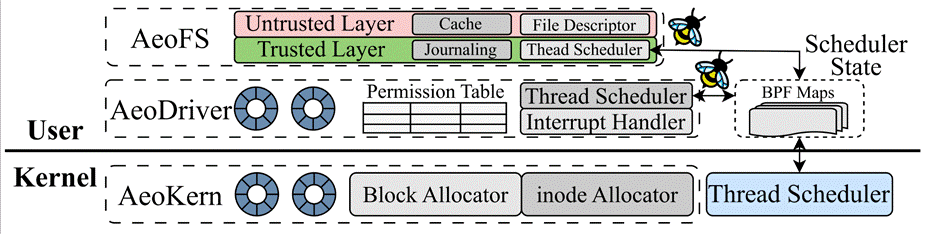
现代虚拟内存管理系统普遍面临性能瓶颈和难以捉摸的并发错误问题,严重影响应用性能并引入安全风险。传统设计依赖软件级(如 Linux 中的 VMA 树)和硬件级(页表)双重抽象,虽提升可移植性,但在并发场景下却因同步两个复杂数据结构而带来巨大挑战。针对此难题,论文《CortenMM: Efficient Memory Management with Strong Correctness Guarantees》提出了一种全新的内存管理系统 CortenMM。其核心突破在于摒弃了现有的软件级抽象设计,指出当前主流 ISA(x86/ARM/RISC-V)的硬件 MMU 格式已高度统一,无需额外的软件抽象层,仅需编程语言特性即可兼容。基于此简化设计,CortenMM 创新性地引入事务化接口及可扩展的锁协议来操作 MMU,有效避免了软件抽象层带来的额外竞争开销,显著提升性能。更重要的是,这种单层设计使得对 MMU 并发操作代码(基础操作及锁协议)的形式化验证成为可能,从而提供了强大的同步正确性保证。在384 核平台上的实验评估表明,经过形式化验证的 CortenMM 在实际应用中性能超越现有设计最高 26 倍。该论文第一作者为北京大学计算机学院博士生张骏扬,作者包括其导师汪小林教授、罗英伟教授和周迪宇助理教授(通讯作者),以及来自蚂蚁集团、上海交通大学、Certik、UCLA 和密歇根理工的合作者。
三、FuseLink: 高效的GPU跨多网卡通信 (OSDI)

随着 AI 应用对于 GPU 通信带宽需求愈发增长,使用单个网卡进行跨机 GPU 通信的方法难以应对巨大的通信需求。并且,简单地堆积多张网卡进行跨机通信又受 PCIe 总线速度限制。而在另一边,机器内部的专用互联(例如 Nvidia NVLink, AMD Infinity Fabric)带宽增长迅猛,远超 PCIe 总线带宽。因而我们提出以下问题:能否利用 GPU 专用互联有效聚合多网卡带宽,实现高带宽的跨机 GPU 通信?本文提出 FuseLink 这一 GPU 通信系统,使用机器内部的高速专用互联在 GPU 之间转发数据并通过多个 GPU 的直连网卡进行通信,有效绕过了 PCIe 总线速率限制。作为一个高效易用的系统,FuseLink 还提供除大带宽传输以外的如下能力:1)网卡冲突避免:FuseLink 只在某块网卡处于空闲状态的时候,将其他 GPU 的通信数据转发到该网卡上,保证 GPU 通信的公平性。例如上图中,FuseLink 监测到 W1 的网卡空闲,因此将 W0 的部分数据转发到 W1 的网卡上。2)应用透明:FuseLink 通过虚拟内存重映射和内存别名的方式,在不改变应用层地址的条件下,分离了内部互联下的数据传输和网络传输,使得跨机通信数据可以在两个独立的传输平面上高效转发,避免了直接转发造成的重复拷贝和重复注册开销。本工作在典型的大带宽传输且网卡负载不均衡场景提升显著,例如大模型服务、专家并行训练、推荐系统的 embedding 传输场景。该论文第一作者为香港科技大学的博士生任正行,作者包括香港科技大学陈凯教授、北京大学的刘古月助理教授,以及来麻省理工学院、Meta 的研究人员。
四、面向空间算力网络的仿真平台 (ATC)
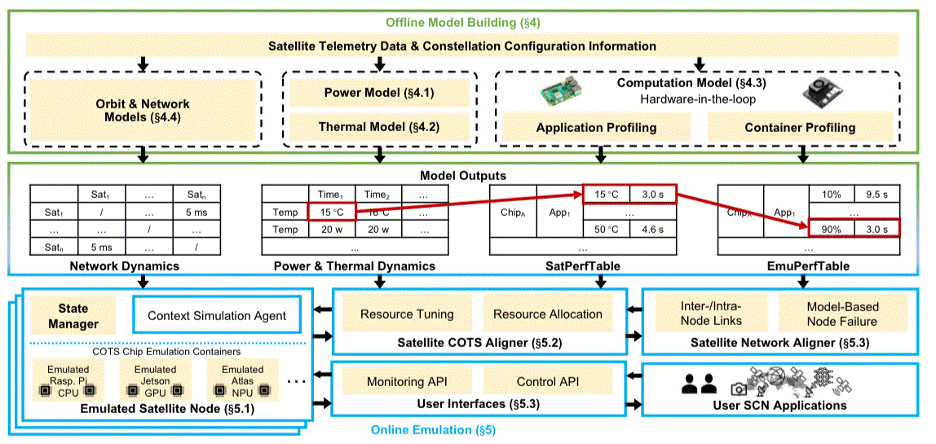
低轨卫星星座规模化和商用现成设备的广泛应用催生了空间算力网络,使地球观测和全球网络服务等应用得以快速发展。然而,太空的严苛环境与星座网络动态拓扑,使空间算力网络应用研发面临高成本与高风险,需要全面的研发工具。论文《Emulating Space Computing Networks with RHONE》提出RHONE仿真框架,通过双阶段建模机制实现高保真空间算力网络仿真:离线阶段分析超过80万条真实卫星遥测数据记录,构建能源模型、热力模型、轨道模型、网络模型及计算模型;在线阶段用Docker容器网络模拟大规模卫星星座,通过卫星COTS校准器动态调整容器资源匹配太空环境约束,结合星座网络校准器注入模型驱动的节点失效机制。实验验证单节点支持700卫星规模,达Starlink单层水平,能源与计算模型误差<5%<>,热力模型误差仅1.3–2.5°C;在安全攻防场景成功复现能源耗尽攻击致节点宕机过程,在地球观测场景量化比较星上处理策略(压缩/检测/推理)的传输能效,为卫星网络安全、星载AI推理、星座资源调度等前沿方向提供高可信实验平台。该论文第一作者为北京大学计算机学院2024级博士生王立楹(导师为许辰人副教授),作者包括北京大学周裕涵、罗兆丰、刘𫍽哲教授、许辰人副教授(通讯作者),北京邮电大学李晴副教授、张东皓和王尚广教授。
五、星绽:一个拥有最小可信基,Linux 兼容,基于 Rust、框内核架构的操作系统 (ATC)
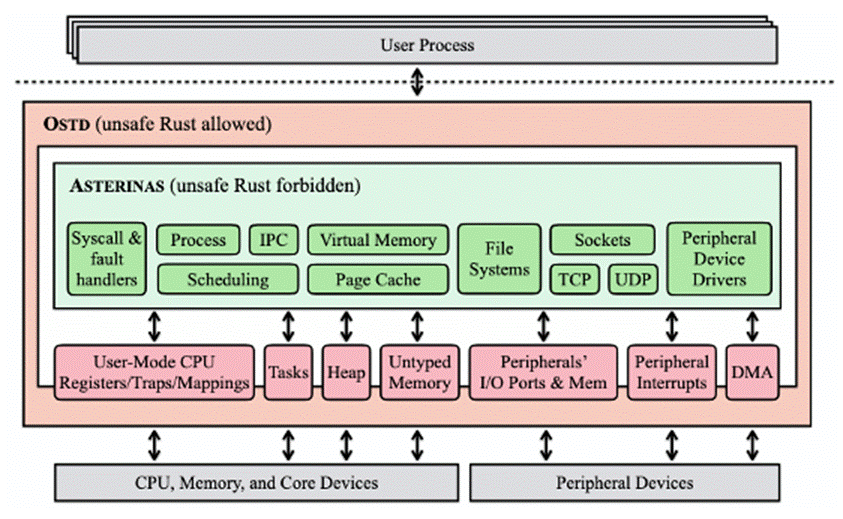
为应对操作系统内核中普遍存在且危害巨大的内存安全问题,论文《Asterinas: A Linux ABI-Compatible, Rust-Based Framekernel OS with a Small and Sound TCB》基于 Rust 语言的内核内特权分离设计,提出了一种创新的操作系统架构“框内核”(framekernel)。使用该架构,研究团队构建了一个功能丰富、通用性强、且具备极简且可靠内存安全可信计算基(TCB)的操作系统。研究团队开发了核心框架 OSTD,并基于此实现了完全兼容 Linux ABI 的操作系统 ASTERINAS。关键突破在于,ASTERINAS 成功将必须使用 unsafe Rust 代码的 TCB 部分缩减至整个代码库的约 14.0%,其余包括设备驱动在内的所有功能均完全使用安全的 Rust 代码(safe Rust)实现。性能评估表明,ASTERINAS 在系统调用密集型基准测试中表现与 Linux 相当(平均标准化性能 1.08),并在 I/O 密集型应用(如 Nginx、Redis)中展现出竞争力。相较于现有 Rust OS(如 Tock、Theseus、RedLeaf),“星绽”架构显著缩小了 TCB 规模,同时保证了高性能,为构建真正安全高效的操作系统提供了切实可行的方案。该论文第一作者为南方科技大学硕士生彭宇科(导师张殷乾教授)和蚂蚁集团田洪亮博士(同等贡献)。合作作者包括北京大学计算机学院博士生张骏扬、李睿涵,罗英伟教授(共同通讯作者)、汪小林教授、许辰人副教授、周迪宇助理教授,蚂蚁集团闫守孟研究员(共同通讯作者)和南方科技大学张殷乾教授(共同通讯作者)等。
六、面向昇腾芯片的模型训练加速:一个用于性能分析、瓶颈诊断与优化的工业级系统 (ATC)
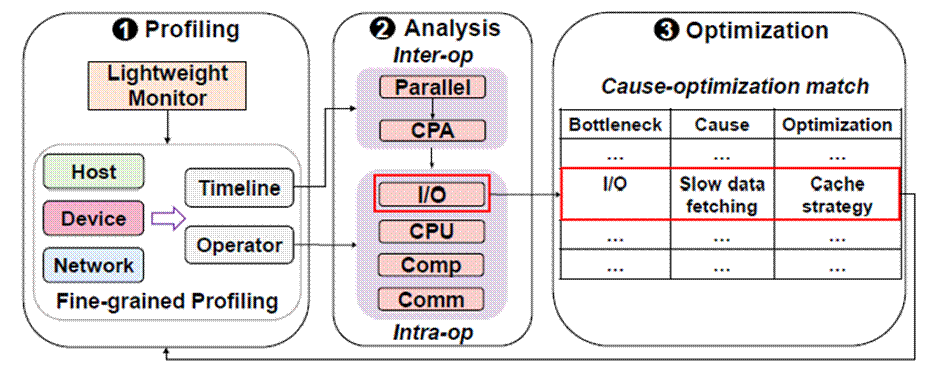
大规模深度学习模型的训练耗时巨大,而提升训练效率面临着诸多挑战,包括如何准确捕获训练过程中的偶发性性能波动,如何在众多影响因素中进行全面准确的瓶颈分析,以及如何在缺乏指导的情况下选择有效的优化策略。论文《Accelerating Model Training on Ascend Chips: An Industrial System for Profiling, Analysis and Optimization》分享了团队在华为昇腾芯片上进行模型训练优化的实践经验,并提出了一个名为Hermes的优化系统,旨在系统地解决性能分析与瓶颈优化难题。首先,Hermes设计了一套“由粗到细”的性能剖析方案,通过轻量级监控器实时发现问题设备,再由细粒度剖析器在不中断训练的情况下获取关键的性能指标。在瓶颈分析上,系统创新地提出了层次化分析框架,首先分析算子间的并行效率,然后深入到算子内部,对I/O、CPU、计算、通信等具体瓶颈的根源进行诊断。最后,基于135个典型优化案例的经验,系统构建了一个优化建议工具,将诊断出的瓶颈根因与行之有效的优化策略进行匹配,并自动给出优化建议。Hermes系统的有效性在广泛的真实大模型训练任务中得到了验证,其优化案例涵盖了自然语言处理、视觉、推荐和MoE等不同模型。该论文第一作者为南京大学的博士生周宇航,作者包括南京大学的田臣教授,北京大学的刘古月助理教授,以及来自鹏城实验室、华为公司、山东大学的研究人员。
七、面向微秒级服务的机架级CPU调度系统 (ATC)

随着云端微服务和高频实时应用的普及,微秒级服务对系统调度延迟和资源利用提出了极高要求。论文《Towards Optimal Rack-scale µs-level CPU Scheduling through In-Network Workload Shaping》提出了一种新型机架级调度系统——Pallas,用于高效调度微秒级请求。该系统创新性地引入“网络内工作负载整形(in-network workload shaping)”的理念,利用可编程交换机主动将混合请求划分为同质请求组,并在交换机中完成分组调度,从而在根本上避免服务器侧的请求堵塞问题(Head-of-line Blocking)。随后,Pallas对这些同质请求执行组内负载均衡,并在服务器端采用简单的集中式FCFS调度,实现近乎最优的尾延迟。为了适应动态负载变化和突发流量,Pallas还设计了请求回弹(request bouncing)机制以平滑策略切换过程中的性能波动,并提出无悔(no-regret)的请求克隆策略,在局部过载时将请求复制至低负载组,从而屏蔽瞬时尖峰带来的尾延迟膨胀。Pallas已在真实环境中完成原型部署,基于Intel Tofino交换机和8台服务器的测试表明:相比代表性方案RackSched,Pallas在合成负载和真实应用RocksDB下均显著降低尾延迟(最多降低8.5×),并在高负载下实现最高两个数量级的提升,同时具有较好的可扩展性。该论文第一作者为香港科技大学博士生廖旭东,合作作者包括香港科技大学陈凯教授、北京大学的刘古月助理教授等。
